Swing/GetLineText のバックアップ(No.14)
- バックアップ一覧
- 差分 を表示
- 現在との差分 を表示
- 現在との差分 - Visual を表示
- ソース を表示
- Swing/GetLineText へ行く。
- 1 (2006-10-10 (火) 14:36:01)
- 2 (2006-11-06 (月) 13:06:59)
- 3 (2006-11-10 (金) 13:50:48)
- 4 (2007-05-07 (月) 13:55:23)
- 5 (2007-05-27 (日) 01:31:30)
- 6 (2007-06-04 (月) 15:08:35)
- 7 (2007-12-10 (月) 20:48:52)
- 8 (2012-02-09 (木) 12:16:59)
- 9 (2012-06-19 (火) 14:55:23)
- 10 (2013-02-22 (金) 19:02:46)
- 11 (2014-12-18 (木) 17:17:10)
- 12 (2015-10-15 (木) 00:18:22)
- 13 (2016-05-30 (月) 16:27:12)
- 14 (2016-09-17 (土) 20:53:53)
- 15 (2017-10-26 (木) 10:59:52)
- 16 (2019-04-11 (木) 13:24:20)
- 17 (2021-01-23 (土) 21:35:26)
- 18 (2023-07-07 (金) 13:57:47)
- 19 (2025-01-03 (金) 08:57:02)
- 20 (2025-01-03 (金) 09:01:23)
- 21 (2025-01-03 (金) 09:02:38)
- 22 (2025-01-03 (金) 09:03:21)
- 23 (2025-01-03 (金) 09:04:02)
- 24 (2025-06-19 (木) 12:41:37)
- 25 (2025-06-19 (木) 12:43:47)
- category: swing
folder: GetLineText
title: JTextAreaから一行ずつ文字列を取得
tags: [JTextArea, StringTokenizer, LineNumberReader]
author: aterai
pubdate: 2006-10-09
description: JTextAreaなどのテキストコンポーネントから一行ずつ文字列を取り出してそれを処理します。
image:
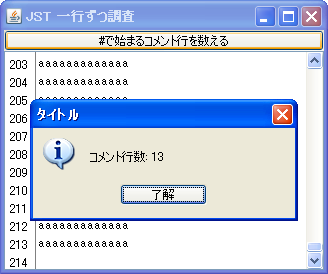
概要
JTextAreaなどのテキストコンポーネントから一行ずつ文字列を取り出してそれを処理します。
Screenshot

Advertisement
サンプルコード
int count = 0;
StringTokenizer st = new StringTokenizer(textArea.getText(), "\n");
while (st.hasMoreTokens()) {
if (st.nextToken().codePointAt(0) == '#') {
count++;
}
}
解説
上記のサンプルでは、JTextArea#getText()ですべてのテキストを取得し、StringTokenizerを使って行毎に分解しています。returnDelimsフラグがfalseなので、トークンが空行になることはありません。
String#split(...)を使用する場合- 空行あり
for (String line: textArea.getText().split("\\n")) {
if (!line.isEmpty() && line.codePointAt(0) == '#') {
count++;
}
}
LineNumberReaderを使用する場合- 空行あり
try (LineNumberReader lnr = new LineNumberReader(new StringReader(textArea.getText()))) {
String line = null;
while ((line = lnr.readLine()) != null) {
if (!line.isEmpty() && line.codePointAt(0) == '#') {
count++;
}
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
Element#getElementCount()を使用する場合- 空行なし(
Elementには少なくとも長さ1の改行が存在する)
- 空行なし(
Document doc = textArea.getDocument();
Element root = doc.getDefaultRootElement();
try {
for (int i = 0; i < root.getElementCount(); i++) {
Element elem = root.getElement(i);
String line = doc.getText(elem.getStartOffset(), elem.getEndOffset() - elem.getStartOffset());
if (line.codePointAt(0) == '#') {
count++;
}
}
} catch (BadLocationException ble) {
ble.printStackTrace();
}